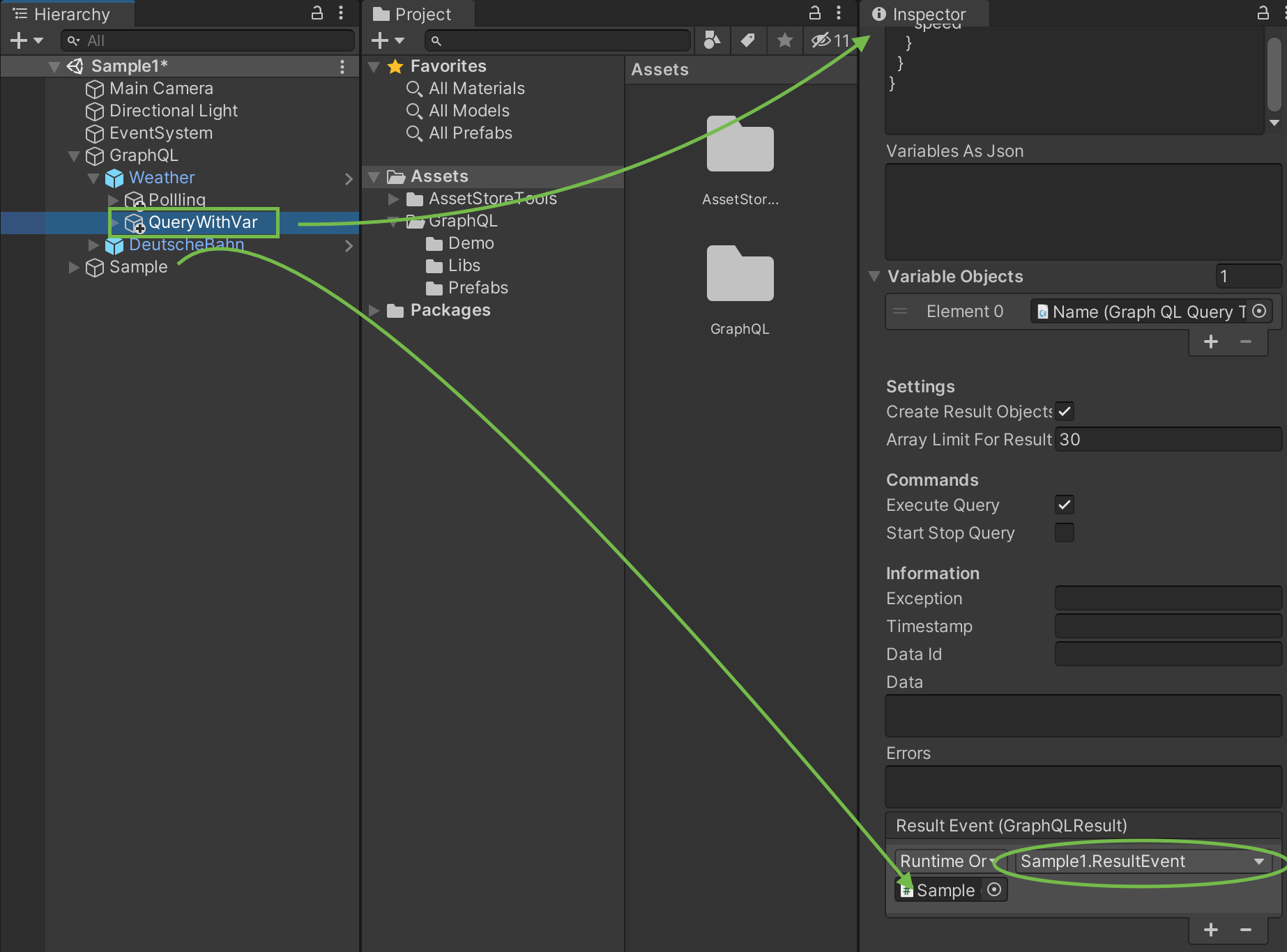
Here is a simple HTML page which fetches data from the OPC UA Automation Gateway “Frankenstein”. It uses HTTP and simple GraphQL queries to fetch the data from the Automation Gateway and display it with Google Gauges. It is very simple and it is periodically polling the data. GraphQL can also handle subscription, but then you need to setup a Websocket connection.
<html>
<head>
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<script type="text/javascript">
google.charts.load('current', {'packages':['gauge']});
google.charts.setOnLoadCallback(drawChart);
var data = null
var options = null
var chart = null
function drawChart() {
data = google.visualization.arrayToDataTable([
['Label', 'Value'],
['Tank 1', 0],
['Tank 2', 0],
['Tank 3', 0],
]);
options = {
width: 1000, height: 400,
redFrom: 90, redTo: 100,
yellowFrom: 75, yellowTo: 90,
minorTicks: 5
};
chart = new google.visualization.Gauge(document.getElementById('chart_div'));
chart.draw(data, options);
}
function refresh() {
const request = new XMLHttpRequest();
const url ='http://localhost:4000/graphql';
request.open("POST", url, true);
request.setRequestHeader("Content-Type", "application/json");
request_data = {
"query": `{
Systems {
unified1 {
HmiRuntime {
HMI_RT_5 {
Tags {
Tank1_Level { Value { Value } }
Tank2_Level { Value { Value } }
Tank3_Level { Value { Value } }
}
}
}
}
}
}`
}
request.send(JSON.stringify(request_data));
request.onreadystatechange = function() {
if (this.readyState==4 /* DONE */ && this.status==200) {
const result = JSON.parse(request.responseText).data
const x = result.Systems
data.setValue(0, 1, x.unified1.HmiRuntime.HMI_RT_5.Tags.Tank1_Level.Value.Value);
data.setValue(1, 1, x.unified1.HmiRuntime.HMI_RT_5.Tags.Tank2_Level.Value.Value);
data.setValue(2, 1, x.unified1.HmiRuntime.HMI_RT_5.Tags.Tank3_Level.Value.Value);
chart.draw(data, options);
}
}
}
setInterval(refresh, 250)
</script>
</head>
<body>
<div id="chart_div" style="width: 400px; height: 120px;"></div>
<!--<button name="refresh" onclick="refresh()">Refresh</button>-->
</body>
</html>