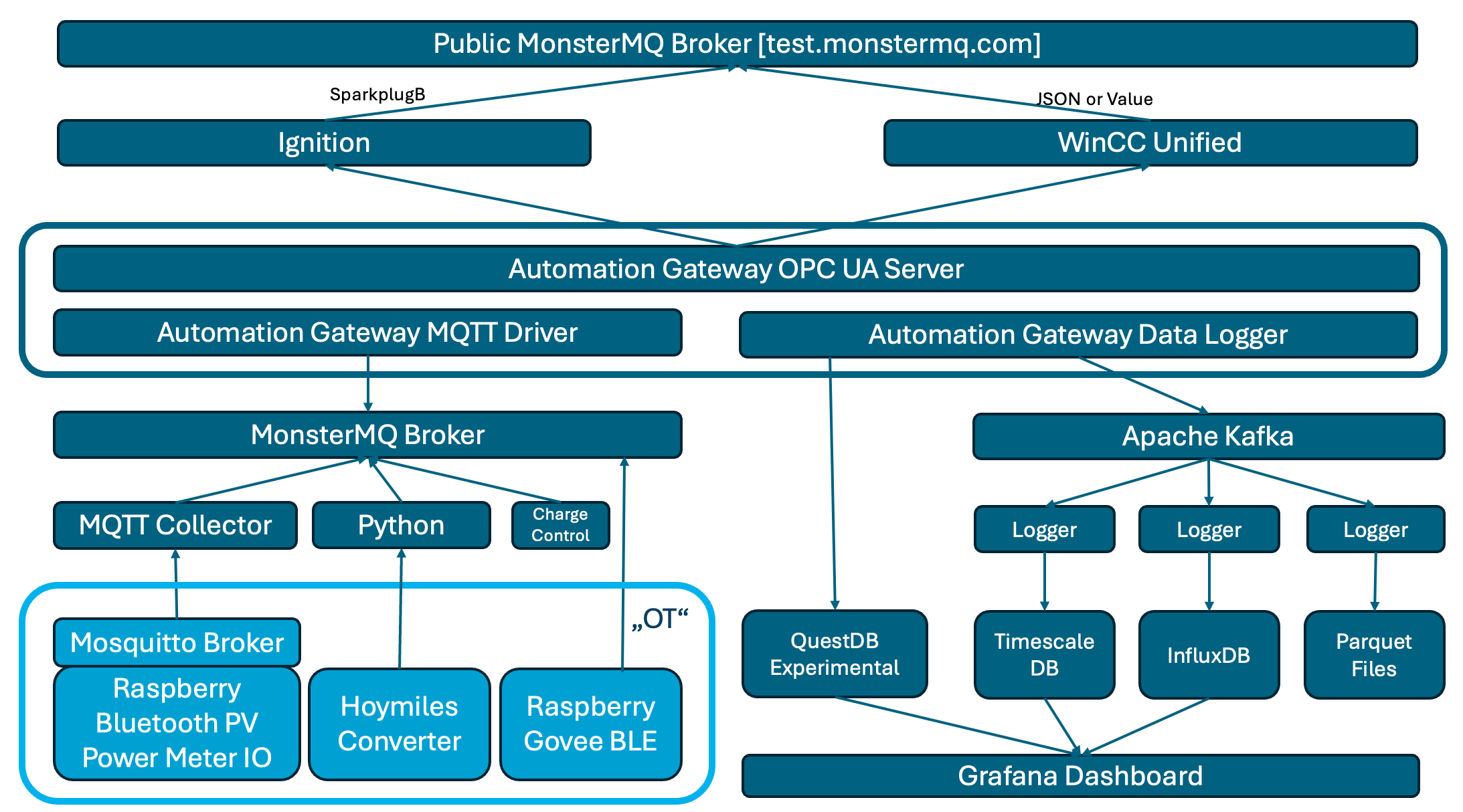
My home automation setup has been an ongoing project, evolving over the last 10–15 years. It started with a simple goal: to track data from my photovoltaic (PV) system, power meters, and temperature sensors, all connected through Raspberry Pi devices. It started with Oracle and over time, it’s grown into a more complex architecture that incorporates multiple layers of data collection, processing, and visualization.
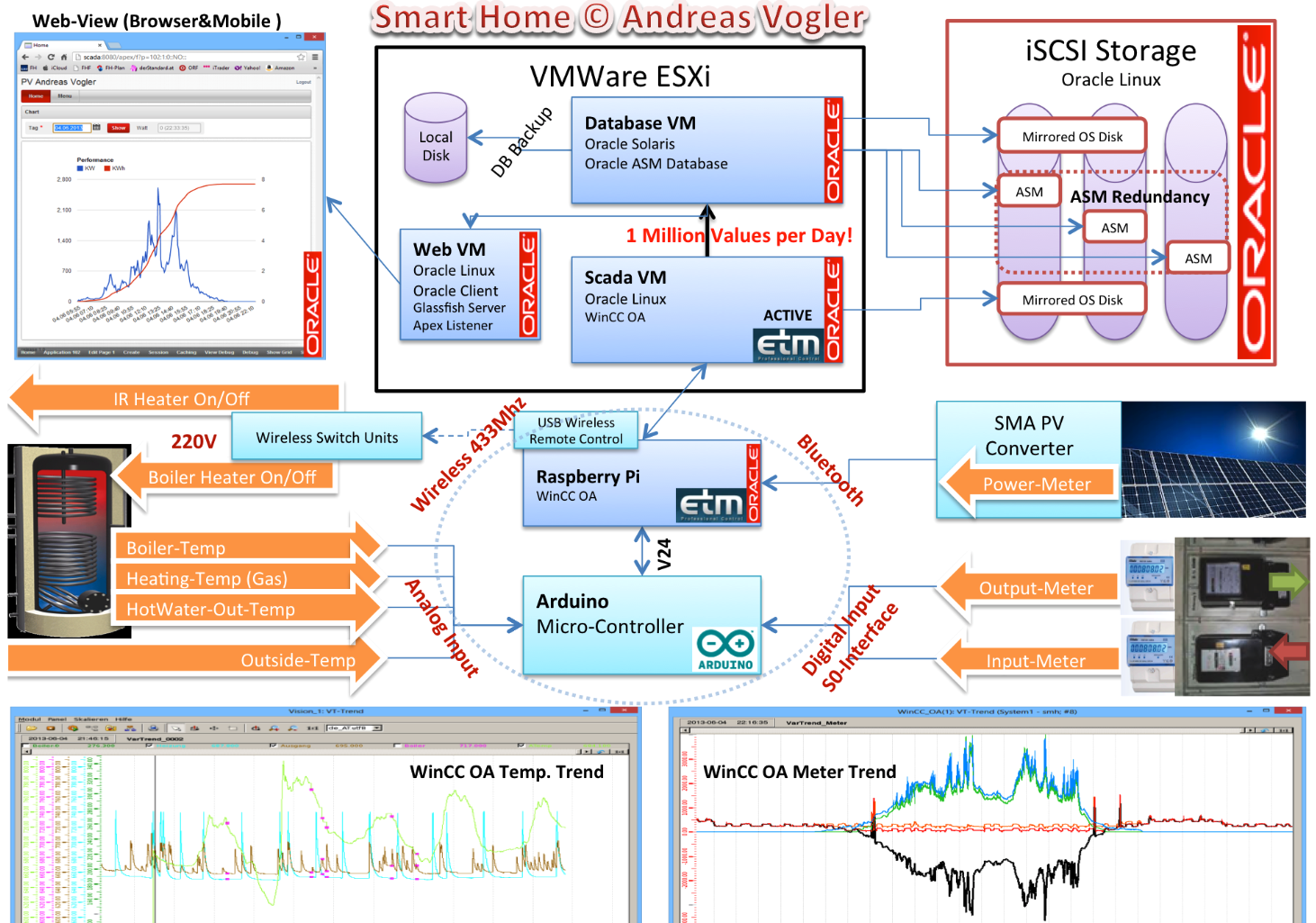
1. Data Collection with Raspberry Pi and MQTT
At the core of my setup are Raspberry Pi devices that connect various sensors, including those for monitoring power generation (PV) by bluetooth, power consumption by meters giving digital signals, and temperature sensors. These Pi devices act as data collectors, feeding data into a local Mosquitto broker. A local broker on the device can serve as a short-term buffer, before it’s synchronized to my central MonsterMQ broker, by using a persistant session and QoS>0.
2. MonsterMQ Broker as the Central Hub
The MonsterMQ broker is the central point where data from all sources is collected. It serves as a bridge, collecting data from the local Mosquitto broker and preparing it for further processing and storage. Before building my own broker, MonsterMQ, I used Mosquitto. Now that I have my own broker, I use MonsterMQ, both to ensure it gets thoroughly tested and to leverage its features. Additionally, in the future, I can use MonsterMQ to store incoming values directly in Apache Kafka. As a database engineer, I appreciate MonsterMQ because it allows me to view the broker’s current state by querying a PostgreSQL database. This lets me see connected clients, their connection details, source IP addresses, and all subscriptions with their parameters..
3. Automation-Gateway for Data Flexibility
To expand the possibilities of what I can do with the data, I use the Automation-Gateway. This tool collects values from MonsterMQ and serves two primary functions:
- Integration with Apache Kafka: By publishing data to Apache Kafka, I maintain a reliable stream that acts as an intermediary between my data sources and the storage databases. This setup provides resilience, allowing me to manage and maintain the databases independently while keeping the data history intact in Kafka.
- OPC UA Server Exposure: The Automation-Gateway also exposes data as an OPC UA server, making it accessible to industrial platforms and clients that communicate over OPC UA. This can be achieved just with a simple YAML configuration file.
4. Experimental Integrations: Ignition and WinCC Unified
On top of this setup, I’ve added experimental connections to Ignition and WinCC Unified. Both of these platforms connect to the Automation-Gateway OPC UA Server. Just for testing those systems are publishing values to my public MQTT broker at test.monstermq.com. While these integrations aren’t necessary, they’re helpful for testing and exploring new capabilities.
5. Long-Term Data Storage with TimescaleDB, QuestDB, and InfluxDB
Data from Kafka is stored in multiple databases:
- InfluxDB: My home-automation started with Oracle and then moved to InfluxDB
- TimescaleDB: Since I am still an advanced SQL user, I needed a database with strong SQL capabilities. Therefore, I added TimescaleDB and imported historical data into it.
Amount of records as of today: 1_773_659_197
Additinally the Automation-Gateway is writing the data now to QuestDB. It is used for experimental data logging and alternative time-series database exploration. Potentially will replace the other databases. I was blown away by how quickly I was able to import 1.5 billion historical data points into QuestDB.
These databases serve as long-term storage solutions, allowing me to create detailed dashboards in Grafana. By keeping Kafka as the layer between my data sources and the databases, I ensure flexibility for database maintenance, as Kafka retains the historical data.
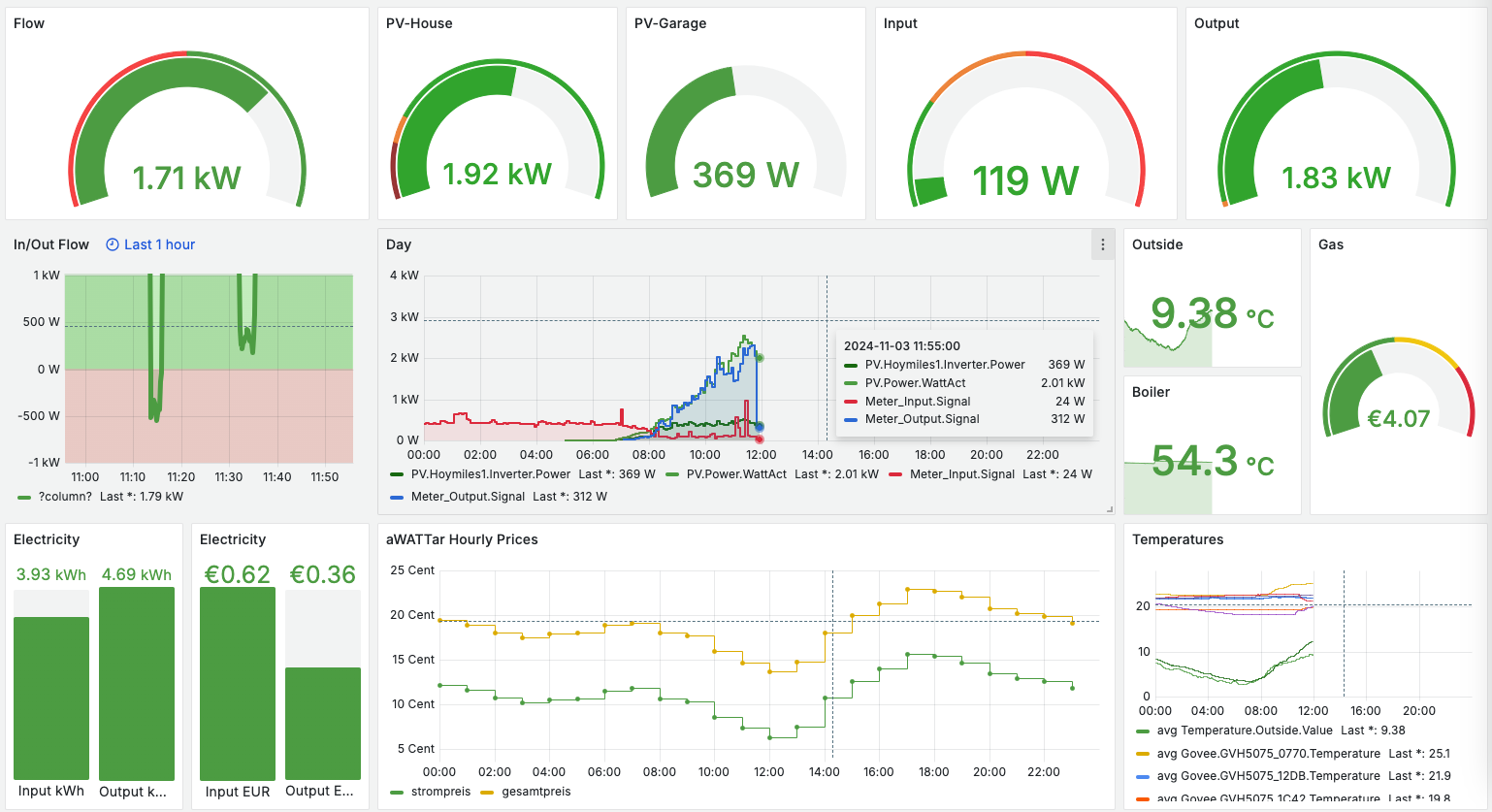
6. Data Logging with MonsterMQ
The public MonsterMQ broker is configured to write data of topics below “grafana/#” directly into a TimescaleDB table. This setup allows you to see updates in Grafana whenever new data is published. In this specific Grafana dashboard configuration, if you publish a JSON object with a key ‘value’ and a numeric value, such as {“value”: 42}, it will appear on the dashboard almost instantly. Here is a public dashboard.
select
time, array_to_string(topic,'/') as topic,
(payload_json->>'value')::numeric as value
from grafanaarchive
where $__timeFilter(time)
and payload_json->>'value' is not null
and payload_json->>'value' ~ '^[0-9]+(\.[0-9]+)?$'
order by time asc7. SparkplugB Decoding with MonsterMQ
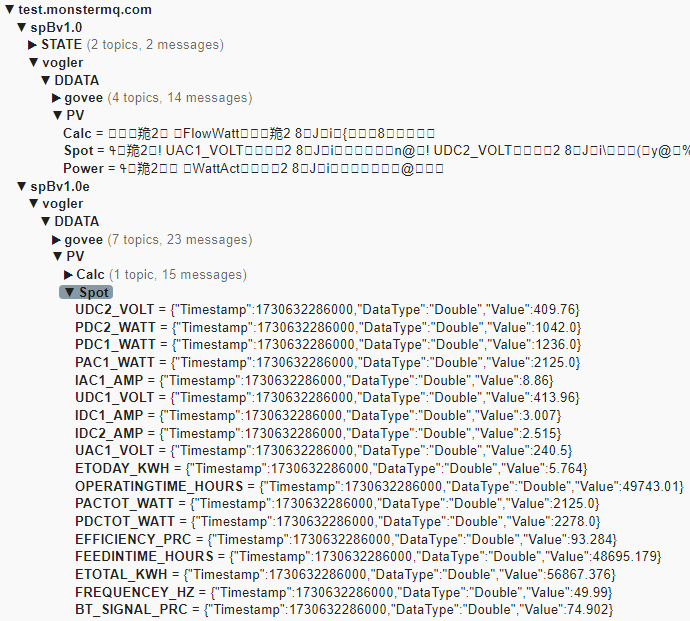
The public MonsterMQ broker is configured to decode and expand SparkplugB messages. Expanded messages can be found under the topic “spBv1.0e“. Ignition publishes some of my home automation data via SparkplugB to the public broker, and you’re welcome to publish your own SparkplugB messages here as well.
Final Thoughts
This setup is the result of years of experimentation and adaptation to new tools. In theory, I could simplify parts of it, for example, by replacing more components with the Automation-Gateway. But I appreciate having Kafka as the buffer between data sources and databases – it offers flexibility for maintenance and helps preserve historical data.
Feel free to test the public MonsterMQ broker at test.monstermq.com. And if you’re curious, publish a JSON object with a “value” key to grafana/something to see it immediately reflected in the Grafana dashboard!