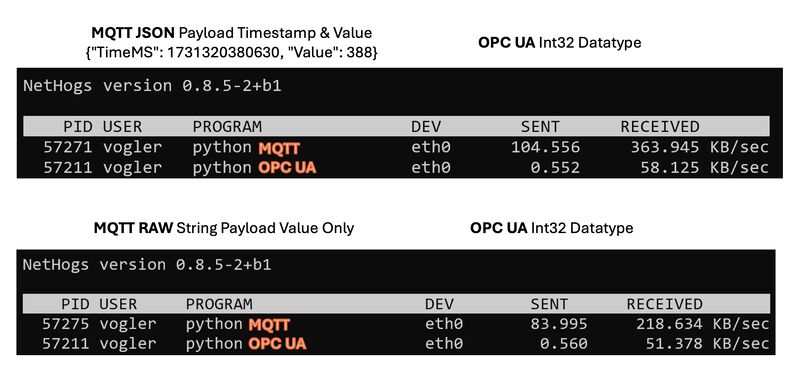
🤔 I often heared about claims that MQTT requires less bandwidth than OPC UA. In my own testing, I found the opposite to be true!
🧪 I took a tree of over 3,500 topics, changing every topic once a second and replicated the exact same structure in OPC UA. In MQTT I was using a simple JSON payload of TimeMS plus the Value (just to note: OPC UA transmits more information than that). I also tried a version with just the plain value as a string. Then, I compared the network I/O stats of client programs subscribing to all those tags, both for OPC UA and MQTT, and confirmed that both clients are receiving all values.
👉 MQTT didn’t show a bandwidth advantage – in fact, it used four to six times the bandwidth of OPC UA in this setup! See the results. 200 KB/s vs 50 KB/s
And, to be honest, it makes sense: every single value change in MQTT includes the full topic name (enterprise/site/area/cell/…), creating a high overhead compared to OPC UA.
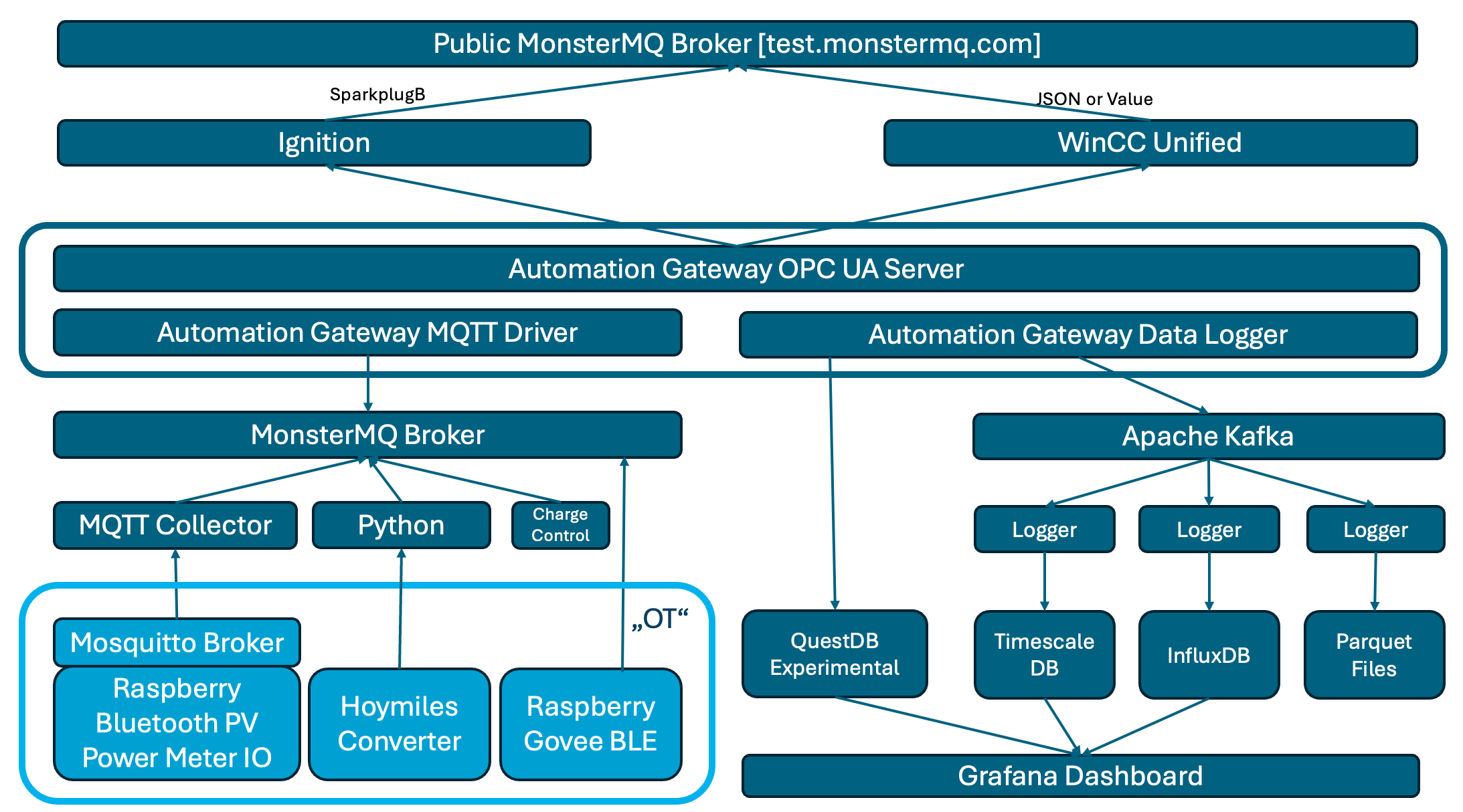
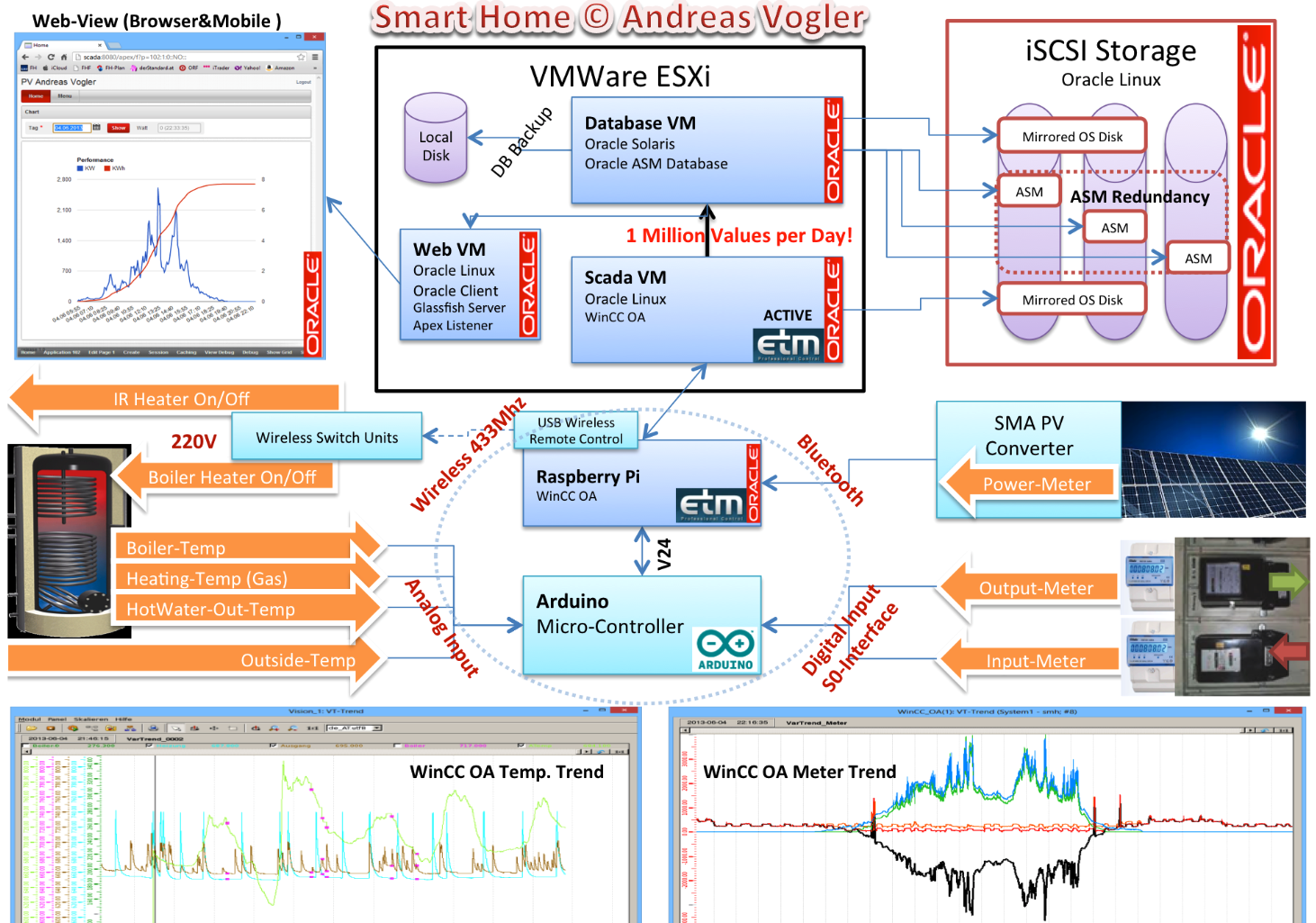
My home automation setup has been an ongoing project, evolving over the last 10–15 years. It started with a simple goal: to track data from my photovoltaic (PV) system, power meters, and temperature sensors, all connected through Raspberry Pi devices. It started with Oracle and over time, it’s grown into a more complex architecture that incorporates multiple layers of data collection, processing, and visualization.
1. Data Collection with Raspberry Pi and MQTT
At the core of my setup are Raspberry Pi devices that connect various sensors, including those for monitoring power generation (PV) by bluetooth, power consumption by meters giving digital signals, and temperature sensors. These Pi devices act as data collectors, feeding data into a localMosquitto broker. A local broker on the device can serve as a short-term buffer, before it’s synchronized to my centralMonsterMQ broker, by using a persistant session and QoS>0.
2. MonsterMQ Broker as the Central Hub
The MonsterMQ broker is the central point where data from all sources is collected. It serves as a bridge, collecting data from the local Mosquitto broker and preparing it for further processing and storage. Before building my own broker, MonsterMQ, I used Mosquitto. Now that I have my own broker, I use MonsterMQ, both to ensure it gets thoroughly tested and to leverage its features. Additionally, in the future, I can use MonsterMQ to store incoming values directly in Apache Kafka. As a database engineer, I appreciate MonsterMQ because it allows me to view the broker’s current state by querying a PostgreSQL database. This lets me see connected clients, their connection details, source IP addresses, and all subscriptions with their parameters..
3. Automation-Gateway for Data Flexibility
To expand the possibilities of what I can do with the data, I use the Automation-Gateway. This tool collects values from MonsterMQ and serves two primary functions:
Integration with Apache Kafka: By publishing data to Apache Kafka, I maintain a reliable stream that acts as an intermediary between my data sources and the storage databases. This setup provides resilience, allowing me to manage and maintain the databases independently while keeping the data history intact in Kafka.
OPC UA Server Exposure: The Automation-Gateway also exposes data as an OPC UA server, making it accessible to industrial platforms and clients that communicate over OPC UA. This can be achieved just with a simple YAML configuration file.
4. Experimental Integrations: Ignition and WinCC Unified
On top of this setup, I’ve added experimental connections to Ignition and WinCC Unified. Both of these platforms connect to the Automation-Gateway OPC UA Server. Just for testing those systems are publishing values to my public MQTT broker at test.monstermq.com. While these integrations aren’t necessary, they’re helpful for testing and exploring new capabilities.
5. Long-Term Data Storage with TimescaleDB, QuestDB, and InfluxDB
Data from Kafka is stored in multiple databases:
InfluxDB: My home-automation started with Oracle and then moved to InfluxDB
TimescaleDB: Since I am still an advanced SQL user, I needed a database with strong SQL capabilities. Therefore, I added TimescaleDB and imported historical data into it.
Amount of records as of today: 1_773_659_197
Additinally the Automation-Gateway is writing the data now to QuestDB. It is used for experimental data logging and alternative time-series database exploration. Potentially will replace the other databases. I was blown away by how quickly I was able to import 1.5 billion historical data points into QuestDB.
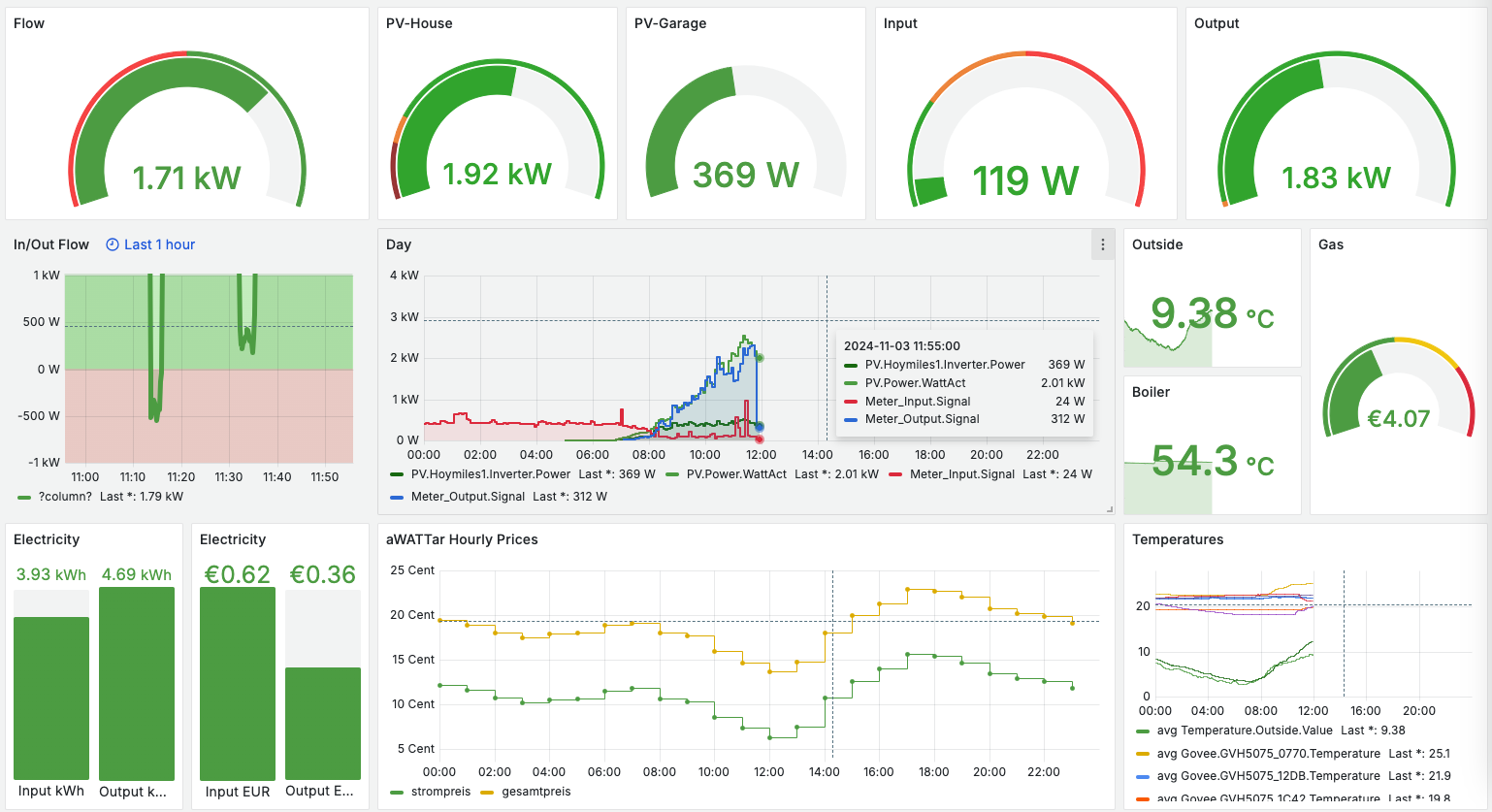
These databases serve as long-term storage solutions, allowing me to create detailed dashboards in Grafana. By keeping Kafka as the layer between my data sources and the databases, I ensure flexibility for database maintenance, as Kafka retains the historical data.
6. Data Logging with MonsterMQ
The public MonsterMQ broker is configured to write data of topics below “grafana/#” directly into a TimescaleDB table. This setup allows you to see updates in Grafana whenever new data is published. In this specific Grafana dashboard configuration, if you publish a JSON object with a key ‘value’ and a numeric value, such as {“value”: 42}, it will appear on the dashboard almost instantly. Here is a public dashboard.
select
time, array_to_string(topic,'/') as topic,
(payload_json->>'value')::numeric as value
from grafanaarchive
where $__timeFilter(time)
and payload_json->>'value' is not null
and payload_json->>'value' ~ '^[0-9]+(\.[0-9]+)?$'
order by time asc
7. SparkplugB Decoding with MonsterMQ
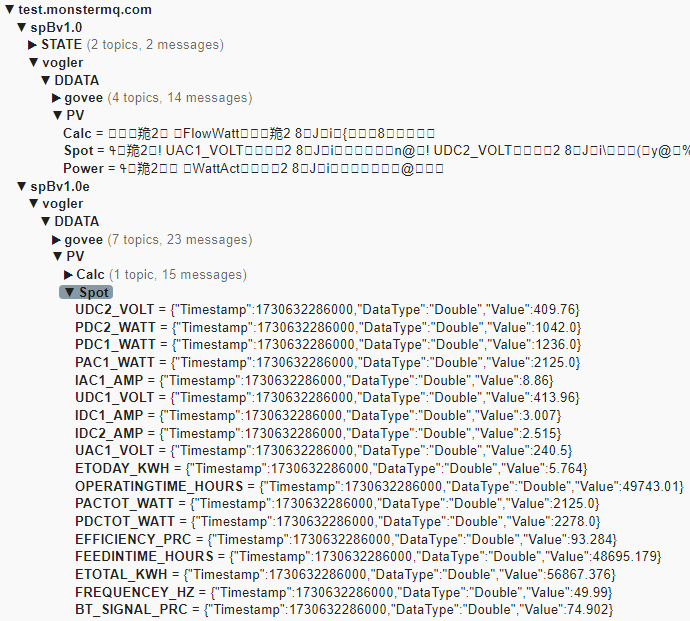
The public MonsterMQ broker is configured to decode and expand SparkplugB messages. Expanded messages can be found under the topic “spBv1.0e“. Ignition publishes some of my home automation data via SparkplugB to the public broker, and you’re welcome to publish your own SparkplugB messages here as well.
Final Thoughts
This setup is the result of years of experimentation and adaptation to new tools. In theory, I could simplify parts of it, for example, by replacing more components with the Automation-Gateway. But I appreciate having Kafka as the buffer between data sources and databases – it offers flexibility for maintenance and helps preserve historical data.
Feel free to test the public MonsterMQ broker at test.monstermq.com. And if you’re curious, publish a JSON object with a “value” key to grafana/something to see it immediately reflected in the Grafana dashboard!
👉 I’ve just installed MonsterMQ on a public virtual machine, hosted by Hetzner – thanks to Jeremy Theocharis awesome post! You can try it out at test.monstermq.com via TCP or Websockets at port 1883. No password, no security. If you want to leave me a message, then use your name as ClientId 😊
🔍 Want to take a look at the TimescaleDB behind it? Connect to the database on the default port 5432 using the (readonly) user “monster” with the password “monster”.
😲 I’ve intentionally set it to store all messages, not just retained ones, in a table “alllastval” for testing purposes.
📈 Additionally, messages published on topics matching “Test/#” will be archived in a history table “testarchive”!
ℹ️ Keep in mind, it’s hosted on a small machine, and every published value is being written and updated in a PostgreSQL table. So, please don’t expect massive throughput or run performance tests.
I’d love for you to try it out. If you find any issues, let me know, or drop an issue on GitHub!
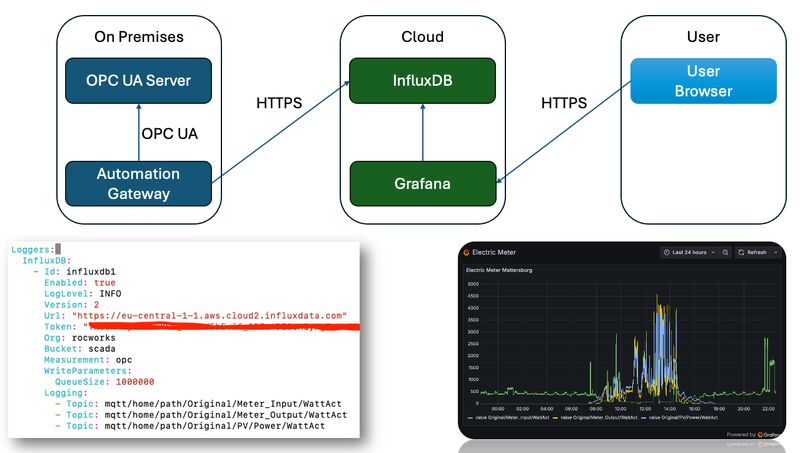
Publish OPC UA and MQTT Data to the Cloud with Automation-Gateway – inspired by a users request 💡
If you have a local 𝗢𝗣𝗖 𝗨𝗔 server or 𝗠𝗤𝗧𝗧 broker and want to bring that data to a 𝗰𝗹𝗼𝘂𝗱-𝗯𝗮𝘀𝗲𝗱 dashboard, Automation-Gateway.com makes it simple. You can easily publish your data to 𝗜𝗻𝗳𝗹𝘂𝘅𝗗𝗕 Cloud and visualize it in 𝗚𝗿𝗮𝗳𝗮𝗻𝗮 — all without complex setups.
I recently added support for InfluxDB V2 to the gateway, allowing you to configure an Influx token and bucket for data publishing. With just a few steps, your local OPC UA or MQTT data can be 𝘀𝘁𝗼𝗿𝗲𝗱 𝗶𝗻 𝘁𝗵𝗲 𝗰𝗹𝗼𝘂𝗱 and displayed in Grafana in real time.
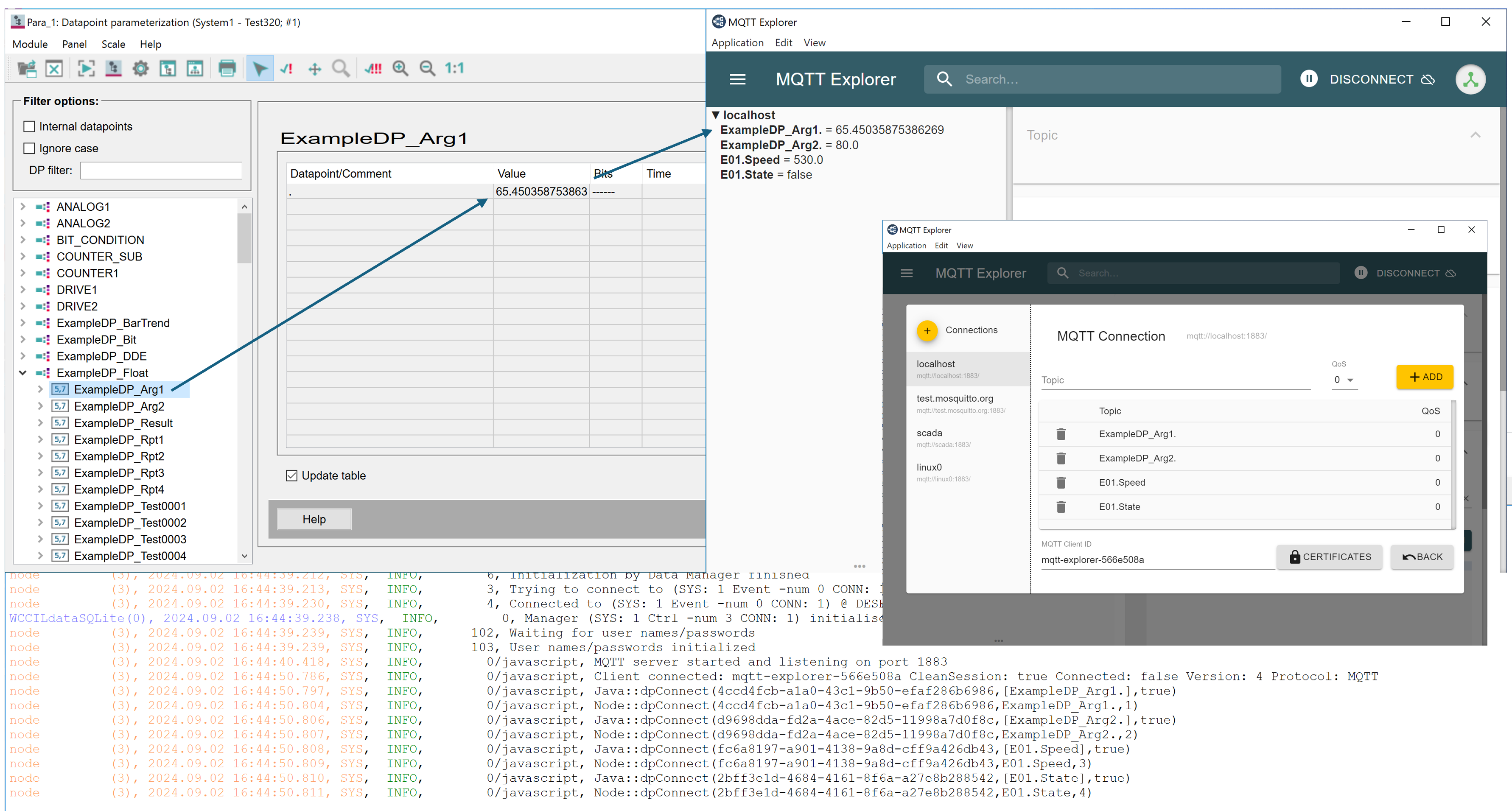
Starting with WinCC OA Version 3.20, you can write your business logic in JavaScript and run them using Node.js, providing direct access to the WinCC OA Runtime.
🙈 With that, I have developed a Kotlin program that acts as an MQTT Broker. When you subscribe to a topic (where the topic name matches a datapoint name), the program will send value changes from the corresponding WinCC OA datapoint to your MQTT client.
❓ But wait, Kotlin is like Java, it runs on the JVM, it is not JavaScript!
💡 Did you know that a Node.js Runtime built with GraalVM exists? It allows you to mix Java and JavaScript. And it also works with WinCC OA.
🤩 You can use JVM based languages and its huge ecosystem to develop business logic with WinCC OA. I have developed a Java library which makes it easier to use the WinCC OA JavaScript functions in Java.
👉 Here it is: https://github.com/vogler75/winccoa-graalvm please note that the example program is provided as an example; it lacks security features and has not been tested for production use. However, it can be extended and customized to meet specific requirements.
⚡ Please be aware that the GraalVM Node.js Runtime is not officially supported by WinCC Open Architecture.
Some weeks ago, someone asked at the #HiveMQ Slack channel if there is any way to run SSH over MQTT…
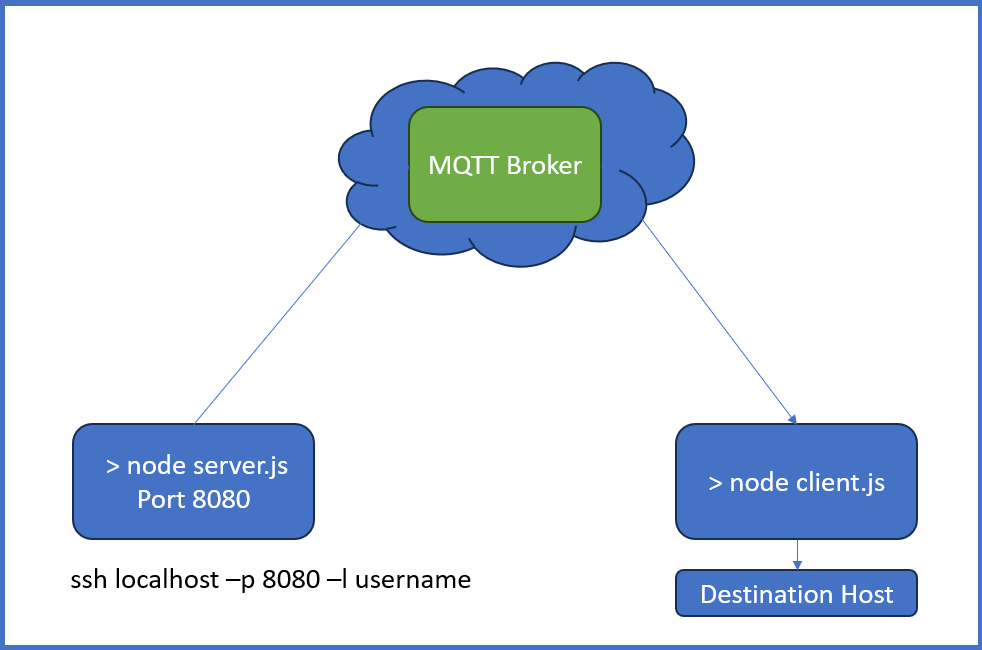
👉 Strange idea? I liked it, and I want to share the TCP-MQTT-TCP bridge I made weeks ago.
🤔 Use Case? Imagine you have IoT’s connected to a central MQTT broker and you want to connect from one to another via SSH, transfer files, expose services, a Webpage, without exposing ports to the public internet or creating a VPN.
⚠️ Be careful and please evaluate and consider the possible security impacts before using this “backdoor man” … the doors …
⚠️ And transferring files over MQTT may increase your cloud bill 🤑
👉It’s on GitHub, it is just a draft and can be used as a template to be extended by your needs.
👀 How to? Start the client.js script at the destination host – or more precisely at a node in the local network where the destination node runs – and start the server.js script on the source node from where you want to connect to the remote/destination host and port. For example, if there is a SSH server running on the destination host+port, then you can do a SSH localhost -p 8080 -l username at your source node, and you will get a SSH connection from the source node to the destination node. And the data is transmitted over MQTT topics.
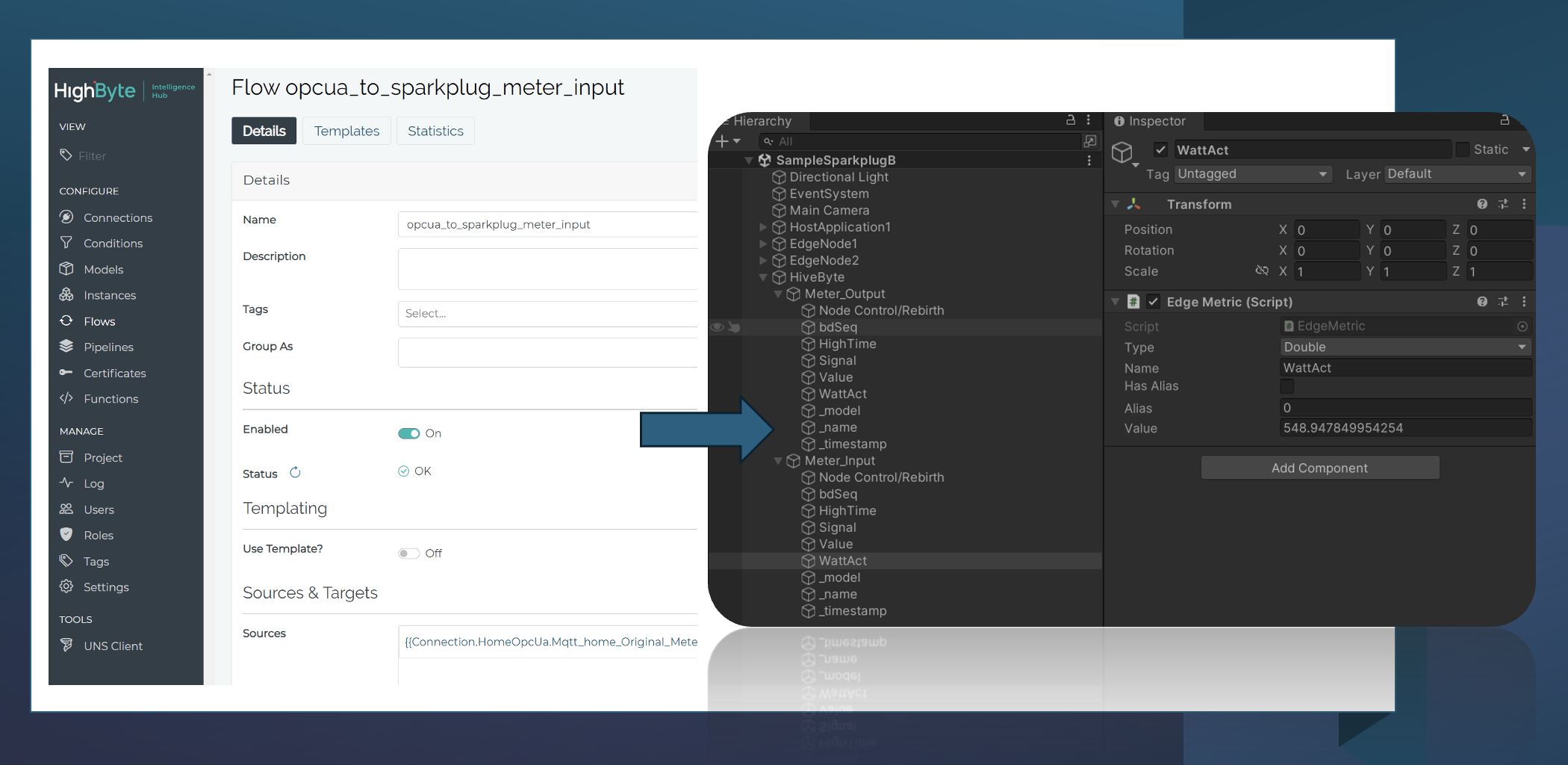
Successfully connected HighByte Intelligence Hub to Unity3D with SparkplugB! ✔
👀 I am sending data from my Automation-Gateway.com to the Intelligence Hub via OPC UA, then the values are published from HighByte to MQTT with the Intelligence Hub SparkplugB connector and then getting consumed in Unity with the MQTT SparkplugB Asset.
👍 Works straight forward and was easy to setup!
🧐 Sparkplug Learning: If a Host Application is not the Primary Host of an Edge Node and it starts up after the Edge Node, it must send the Rebirth command to the Edge Nodes in which it is interested in, to get a birth message with the current/initial values of all the metrics of the nodes. My Unity client ignores incoming metrics of DATA messages which it has not seen before in a BIRTH message…